Pandas는 데이터를 조작하거나
분석을 쉽게하기 위한 Python의 모듈(라이브러리)입니다.
설치를 위해서는 cmd를 열고
pip install pandas
를 입력해줍니다.
그 다음은 모듈을 하나 만들어주고
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import pandas as pd
matplotlib이라는 그래프 그려주는 모듈과 함께 사용해보겠습니다.
먼저 데이터를 불러오려고 하는데
Pandas에는 csv파일의 데이터를 읽어오는 기능이 있습니다.
df = pd.read_csv("C:/Users/sdedu/Desktop/threekingdoms/subway.csv")
read_csv라는 기능인데요.
이 read_csv 기능은 행과 열로 이루어진 2차원 Dataframe으로 불러오게 됩니다.
df = pd.read_csv("C:/Users/sdedu/Desktop/threekingdoms/subway.csv",
names=["언제", "호선", "역", "prn", "frn", "pan", "fan"])
이렇게 names라는 속성을 부여하면 해당 데이터 열의 이름을 부여할 수 있습니다.
df를 출력해보면 이렇게
csv파일의 데이터가 정렬된 데이터로 넘어오게 됩니다.

pandas에는 groupby라는 기능도 있는데
그룹별로 데이터를 집계해주고 요약해주는 기능입니다.
df2 = df.groupby("언제").sum()
print(df2)

이 데이터를 이용해서 그래프를 만들건데요.
plt.plot(range(df2.index.size),df2['prn'], color='#EF9A9A')
plt.plot(range(df2.index.size),df2['frn'], color='yellow')
plt.plot(range(df2.index.size),df2['pan'], color='#90CAF9')
plt.plot(range(df2.index.size),df2['fan'], color='black')
plot에 x좌표에는 인덱스의 크기를 넣어주고,
y좌표에는 각 키값에 해당하는 값을 넣어줍니다.
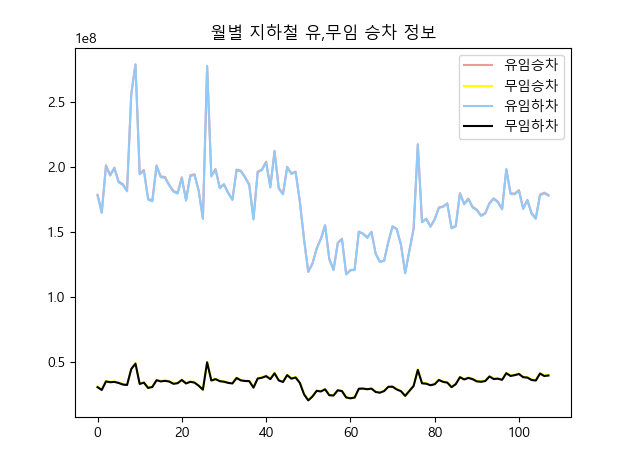
그래프 선은 총 4개인데 겹쳐서
2개로 보이는 상황입니다.
Pandas를 사용해서
데이터를 끌어와보는 실습까지 진행해봤습니다.
'Python' 카테고리의 다른 글
| [Python] Numpy (0) | 2025.03.14 |
|---|---|
| [Python] Colab (0) | 2025.03.14 |
| [Python] 파이썬에서 CSV만드는 법 (0) | 2025.03.10 |
| [Python] DB에 Select하기 (0) | 2025.03.07 |
| [Python] DB에 Insert하기 (0) | 2025.03.07 |



